
AI workloads require significant computing power, especially for machine learning (ML) and deep learning models. GPUs accelerate these workloads. However, the infrastructure used impacts performance. This blog compares Kubernetes and traditional infrastructure for AI workloads, focusing on GPU usage and deployment strategies.
Traditional Infrastructure for AI Workloads
Traditional infrastructure uses physical servers or virtual machines (VMs). This approach has been common for AI model deployment.
Advantages:
- Direct access to GPUs for AI model training.
- Minimal overhead for deploying AI applications.
- Easy control over hardware resources.
Challenges:
- Limited scalability for growing AI workloads.
- Manual updates and deployment tasks.
- Harder to automate GPU resource allocation.
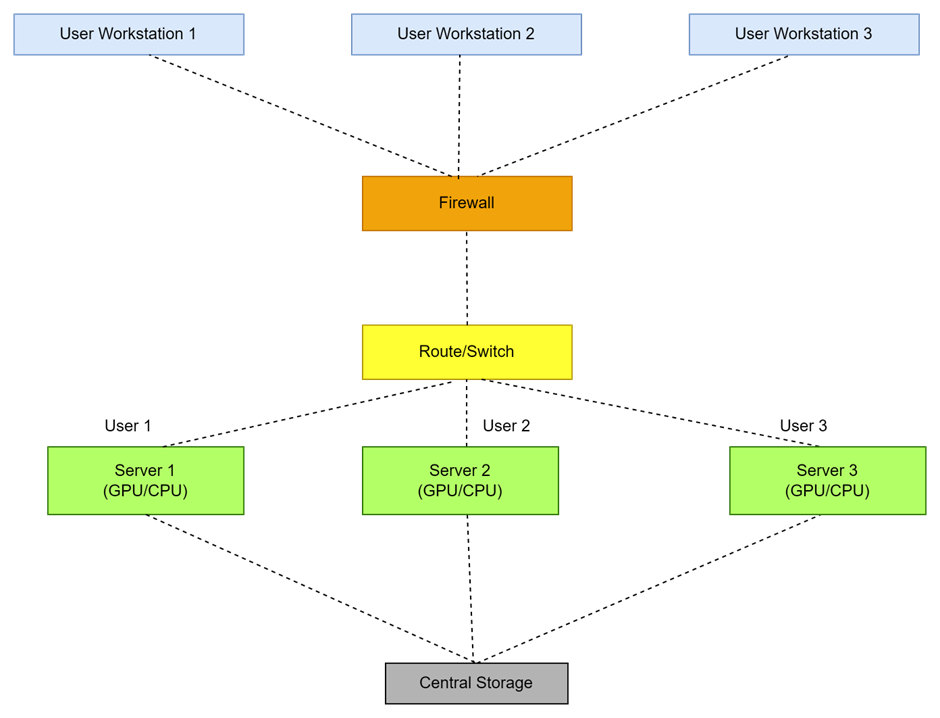
Architecture Flow
- User Workstations: These are individual systems from where users submit AI tasks or data for processing. Users typically connect to the infrastructure through remote desktops or command-line interfaces.
- Firewall: It Acts as a security barrier, ensuring only authorized traffic passes through. It protects the internal network from malicious traffic.
- Router/Switch: This component handles the routing and switching of data packets between devices within the infrastructure. It connects user workstations, servers, and storage.
- Servers with GPUs/CPUs: Each server contains GPUs (for AI computations like training models) and CPUs (for general-purpose processing). These servers process the submitted AI tasks, utilizing their GPUs for high-performance computing.
- Central Storage: A shared storage system where the servers store and access data. Data flows from the central storage to the servers as needed during processing and is sent back once the computation is complete.
Kubernetes for AI Workloads
Kubernetes is a container orchestration platform. It automates the deployment and scaling of AI workloads and supports GPU acceleration.
Advantages:
- Automatic scaling of machine learning models.
- Efficient resource management with Kubernetes GPU scheduling.
- Simplifies deployment and monitoring across multi-cloud environments.
Challenges:
- Initial complexity in setting up Kubernetes with GPUs.
- Requires familiarity with Kubernetes-native tools.
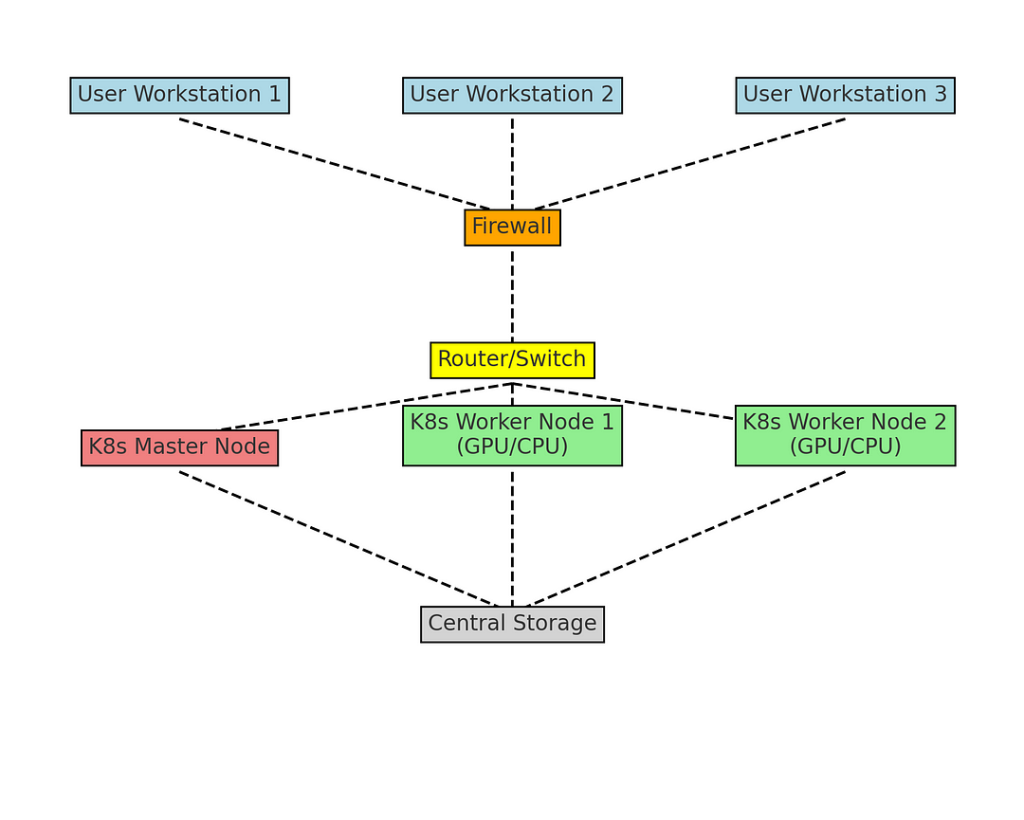
Architecture Flow
- User Workstations: Users submit containerized AI tasks (e.g., TensorFlow jobs) to the Kubernetes cluster from their workstations. They typically use Kubernetes tools like
kubectlor web interfaces. - Firewall: Provides security, ensuring only authenticated traffic reaches the Kubernetes cluster.
- Router/Switch: Manages the network connectivity between user workstations, the Kubernetes master node, and worker nodes.
- Kubernetes Master Node: The central control unit for the Kubernetes cluster, responsible for managing worker nodes, scheduling tasks, and maintaining the desired state of the cluster. It controls the deployment and scaling of AI tasks across the worker nodes.
- Kubernetes Worker Nodes with GPUs: These are the actual servers where containerized AI workloads run. Each node has GPUs for high-performance computations. The master node assigns tasks to these workers based on resource availability.
- Central Storage: A shared system that stores data for AI tasks. All Kubernetes nodes can access the storage, ensuring data is loaded and processed when needed.
When to Use GPUs in Traditional Infrastructure
Use GPUs in traditional infrastructure when:
- A specific GPU type is needed for the workload.
- Manual control over hardware is preferred.
- Scaling is less important.
- The cost of hardware maintenance is manageable.
Traditional infrastructure works best for fixed AI workloads that don’t need frequent changes.
When to Use GPUs in Kubernetes
Use GPUs in Kubernetes when:
- AI workloads need to scale often.
- Automated deployment and monitoring are required.
- The environment is multi-cloud or hybrid.
- Cost efficiency is important in cloud-based GPU instances.
Kubernetes allows for flexibility in scaling and resource management, making it ideal for growing AI workloads.
Both Kubernetes and traditional infrastructure have their advantages for AI workloads. GPUs can be used effectively in both setups depending on scalability, control, and automation needs. Kubernetes is ideal for large-scale, dynamic workloads, while traditional infrastructure is better for fixed, controlled environments.
For a more detailed explanation of NVIDIA GPU Deployment for AI in Kubernetes, check out my blog.
For more information on cloud-native solutions for AI workloads, refer to NVIDIA’s documentation here.

