
Have you ever wanted to chat with your PDFs? Imagine an AI-powered PDF search engine that can extract, index, and query documents just like ChatGPT. In this guide, we’ll build an intelligent document search system using LlamaIndex, Ollama, and DeepSeek-R1. You’ll be able to ask questions about your PDFs and get instant answers!
Why Use AI for Document Search?
Traditional keyword-based search in PDFs is inefficient. AI-powered search allows you to:
- Retrieve context-aware answers instead of just keyword matches.
- Process large documents quickly.
- Ask natural language questions and receive human-like responses.
Prerequisites
Before we begin, ensure you have the following:
- A Linux-based system.
- Ollama installed
- Python 3+ installed with
pip3. - Basic knowledge of Python and command-line usage.
Step 1: Install Dependencies
First, install the necessary libraries and tools:
# Check if Ollama is installed
ollama --version
# Install Python dependencies
apt install python3-pip -y
pip3 install llama-index PyPDF2
# Verify installation
python3 -c "import llama_index; import PyPDF2; print('Dependencies Installed')"
What’s Happening Here?
- Ollama check: Verify if Ollama is installed.
- Python setup: Ensures
pip3is installed. - Package installation: Installs
llama-indexfor AI-powered search andPyPDF2for PDF text extraction.
Step 2: Download and Organize PDFs
Download a sample PDF and organize it in a directory.
# Download a sample PDF
wget https://arxiv.org/pdf/2303.08774.pdf
# Create a directory for PDFs
mkdir data
# Move the PDF into the "data" folder
mv 2303.08774.pdf data/GPT-4.pdf
# Verify the file is in the correct place
ls data/
Step 3: Create a Search Index
Now, we’ll use LlamaIndex to extract text and create embedding using Ollama.
Create a file <strong>create_index.py</strong> and add the following code:
from llama_index.core import SimpleDirectoryReader, VectorStoreIndex
from llama_index.embeddings.ollama import OllamaEmbedding
from llama_index.llms.ollama import Ollama
# Use mxbai-embed-large for embeddings
embed_model = OllamaEmbedding(model_name="mxbai-embed-large")
# Use DeepSeek for inference via Ollama
llm = Ollama(model="deepseek-r1:1.5b")
# Load documents from a directory (where PDFs are stored)
documents = SimpleDirectoryReader(input_dir="./data").load_data()
# Create an index with mxbai embeddings
index = VectorStoreIndex.from_documents(documents, embed_model=embed_model)
# Save the index
index.storage_context.persist(persist_dir="./index")
print("Index created using mxbai embeddings and saved successfully.")
What’s Happening Here?
- SimpleDirectoryReader reads PDF files and extracts text.
- OllamaEmbedding creates embedding for efficient search.
- DeepSeek-R1 is used as the inference model for querying.
- VectorStoreIndex stores and optimizes document search.
Run the script:
python3 create_index.py
Step 4: Query Your Document with AI
Now, Query the index using natural language.
Create <strong>query.py</strong> and add:
from llama_index.core import load_index_from_storage, StorageContext, Settings
from llama_index.llms.ollama import Ollama
from llama_index.embeddings.ollama import OllamaEmbedding
# Explicitly set OllamaEmbedding as the default
Settings.embed_model = OllamaEmbedding(model_name="mxbai-embed-large")
# Define storage context for loading the index
storage_context = StorageContext.from_defaults(persist_dir="./index")
# Load the saved index with the storage context
index = load_index_from_storage(storage_context=storage_context)
# Use DeepSeek-R1 via Ollama for inference
llm = Ollama(model="deepseek-r1:1.5b")
# Create a query engine
query_engine = index.as_query_engine(llm=llm)
# Query the document
query = "What is this document about?"
response = query_engine.query(query)
print("Answer: ", response)
Run the script:
python3 query.py
How It Works
- The index is loaded from storage.
- A query engine is created using DeepSeek-R1.
- The AI understands the document context and retrieves relevant answers.
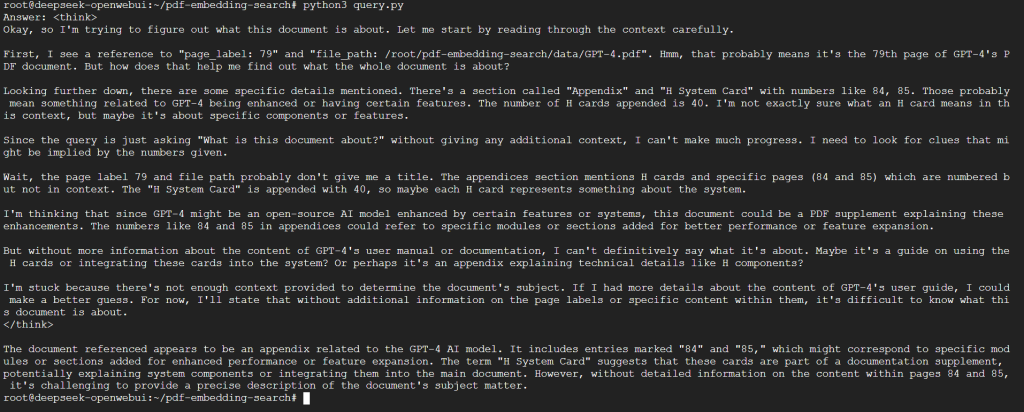
Results
The output should provide a clear and concise answer to your query. You can now ask any question related to your PDF!
What’s Next?
Now that you’ve built an AI-powered PDF search engine, you can:
✅ Add multiple PDFs to enable large-scale document search.
💡 Enhance interactivity by integrating a chatbot UI.
🚀 Deploy the system as a web app for seamless access.

