
In modern AI and machine learning (ML) workloads, NVIDIA GPUs play a crucial role in accelerating both training and inference processes. Kubernetes offers a flexible and scalable platform to orchestrate these workloads. The NVIDIA GPU Operator simplifies the process of setting up GPUs in Kubernetes clusters. In this blog, we will walk through how to set up GPU-based AI model training and inference in Kubernetes by configuring the NVIDIA GPU Operator.
To deploy and manage NVIDIA GPUs efficiently, using a GPU operator is crucial. If you’re interested in a step-by-step deployment guide, check out my YouTube video here:
Prerequisites
Before diving into the installation and setup, ensure you have the following:
- A Kubernetes cluster with at least one GPU-enabled node.
- Kubernetes CLI (
kubectl) installed and configured. - Helm installed for deploying the NVIDIA GPU Operator.
Understanding the NVIDIA GPU Operator
The NVIDIA GPU Operator manages the lifecycle of NVIDIA GPU resources in a Kubernetes cluster. It automates tasks like:
- Driver installation
- GPU monitoring
- GPU resource management for workloads
- Integration with CUDA, NVIDIA Container Toolkit, and other libraries
By using this operator, AI workloads can leverage GPU resources without the need for manual configuration.
NVIDIA GPU Operator Architecture
This diagram shows how the NVIDIA GPU Operator interacts with the Kubernetes cluster and GPU-enabled nodes. It handles driver installation, GPU monitoring, and resource management, ensuring that AI workloads can efficiently use GPU resources.
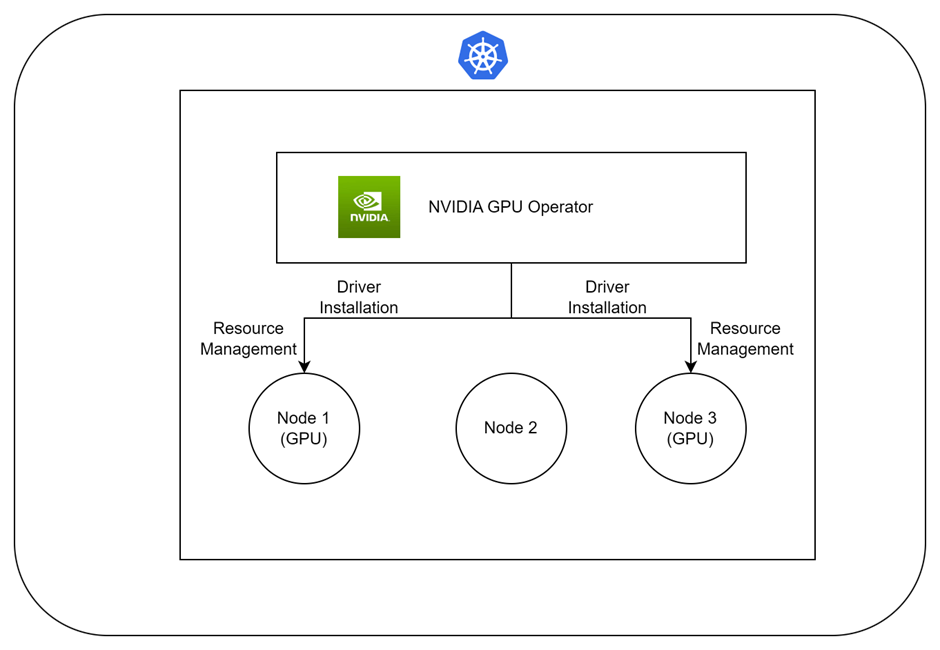
Flow of NVIDIA GPU Operator Architecture:
- Deployment: The NVIDIA GPU Operator is deployed within the Kubernetes cluster.
- Driver Installation: The operator detects GPU-enabled nodes and automatically installs the necessary NVIDIA drivers.
- Resource Management: It configures the NVIDIA device plugin on these nodes to expose GPU resources to Kubernetes pods.
- Ongoing Maintenance: The operator continuously manages and updates GPU resources to ensure optimal performance and compatibility.
For more in-depth details about the NVIDIA GPU Operator, please refer to the official documentation.
Setting Up NVIDIA GPU in Kubernetes
Step 1. Add GPU-enabled Nodes
You must have NVIDIA GPU nodes in a Kubernetes cluster. If you are working on the Public cloud like AWS or GCP choose a GPU instance.
Step 2. Check GPU Availability
After provisioning the GPU nodes, confirm that they are visible in the cluster.
root@rke2-server1:~# kubectl describe nodes | tr -d '\000' | sed -n -e '/^Name/,/Roles/p' -e '/^Capacity/,/Allocatable/p' -e '/^Allocated resources/,/Events/p' | grep -e Name -e nvidia.com | perl -pe 's/\n//' | perl -pe 's/Name:/\n/g' | sed 's/nvidia.com\/gpu:\?//g' | sed '1s/^/Node Available(GPUs) Used(GPUs)/' | sed 's/$/ 0 0 0/' | awk '{print $1, $2, $3}' | column -tInstalling NVIDIA GPU Operator
The NVIDIA GPU Operator is designed to manage NVIDIA drivers, container runtime, and monitoring tools. To install it:
Step 1. Add the NVIDIA Helm Repository:
root@rke2-server1:~# helm repo add nvidia https://nvidia.github.io/gpu-operator
root@rke2-server1:~# helm repo updateStep 2. Install the GPU Operator via Helm
root@rke2-server1:~ helm install test gpu-operator --namespace gpu-operator --create-namespace --wait -f gpu-values.yamlStep 3. Verify the installation
root@rke2-server1:~# kubectl get pod -n gpu-operator
NAME READY STATUS RESTARTS AGE
gpu-feature-discovery-7knsw 1/1 Running 0 1d
gpu-operator-7c4d47c567-xzgmv 1/1 Running 2 (1d ago) 1d
nvidia-container-toolkit-daemonset-bj459 1/1 Running 0 1d
nvidia-cuda-validator-g2pgq 0/1 Completed 0 1d
nvidia-dcgm-exporter-ggldn 1/1 Running 3 (1d ago) 1d
nvidia-dcgm-p5frp 1/1 Running 0 1d
nvidia-device-plugin-daemonset-2s5km 1/1 Running 0 1d
nvidia-driver-daemonset-wzwpp 1/1 Running 8 (1d ago) 1d
nvidia-operator-validator-d4zcq 1/1 Running 0 1d
test-node-feature-discovery-master-6f7888bf6-d4qxg 1/1 Running 7 (1d ago) 1d
test-node-feature-discovery-worker-b9q64 1/1 Running 8 (1d ago) 1d
test-node-feature-discovery-worker-wtfm6 1/1 Running 2 (1d ago) 1d
test-node-feature-discovery-worker-zlncg 1/1 Running 8 (1d ago) 1d
root@rke2-server1:~#This command shows the status of NVIDIA’s GPU operator components like driver and CUDA.
Running AI Model Training on Kubernetes
Once the GPU operator is installed, we can run training workloads on the cluster.
Step 1. Prepare the AI Model:
Ensure the machine learning model is packaged in a GPU-compatible container. For instance, use TensorFlow images from the NVIDIA NGC repository:
root@rke2-server1:~# docker pull nvcr.io/nvidia/tensorflow:21.09-tf2-py3Step 2. Create a Kubernetes Pod for GPU Training:
Define the pod with GPU resource requests:
apiVersion: v1
kind: Pod
metadata:
name: gpu-training-jon
spec:
containers:
- name: tensorflow-gpu
image: nvcr.io/nvidia/tensorflow:21.09-tf2-py3
resources:
limits:
nvidia.com/gpu: "1"
command: ["python", "train.py"]Step 3. Deploy the Training Job:
Deploy the pod using the following command:
root@rke2-server1:~# kubectl apply -f gpu-training-job.yamlThis will start the model training process, using the requested GPU resources.
Optimizing GPU Utilization in Kubernetes
To ensure efficient use of GPUs for AI training, consider the following practices:
1. Adjust GPU Requests
Properly configuring GPU requests ensures that your workloads receive the appropriate amount of GPU resources, which can significantly impact performance and cost.
Best Practices:
- Specify GPU Requests and Limits: Use Kubernetes resource requests and limits to specify the number of GPUs required by each pod. This helps the scheduler to make informed decisions about resource allocation.
Example YAML Configuration:
resources:
requests:
nvidia.com/gpu: "1"
limits:
nvidia.com/gpu: "1"- Balance Workloads: Avoid overcommitting GPU to prevent resource contention and ensure that each workload gets the necessary resources.
- Evaluate Utilization Patterns: Regularly assess the GPU usage patterns to adjust requests and limits based on actual needs and workload behaviour.
2. Monitor GPU Performance
Monitoring GPU performance helps in identifying bottlenecks, optimizing usage, and ensuring that GPU are being effectively utilized.
Best Practices:
- Use Monitoring Tools: Employ monitoring tools like Prometheus and NVIDIA DCGM to collect and visualize GPU metrics.
- Prometheus: Integrates with exporters to gather metrics from GPU resources and provides dashboards for performance analysis.
- DCGM: NVIDIA’s Data Center GPU Manager provides detailed insights into GPU health, utilization, and performance.
- Set Up Alerts: Configure alerts to notify you of any performance issues or anomalies, such as high utilization or overheating.
- Analyze Performance Data: Regularly review performance metrics to identify trends and optimize resource allocation. Look for patterns like frequent throttling or underutilization.
3. Optimize GPU Workloads
Efficiently managing GPU workloads can lead to better performance and resource utilization.
Best Practices:
- Batch Processing: For AI training, batch processing can make better use of GPU resources by processing multiple inputs in parallel.
- Optimize Code: Ensure that your AI models and training code are optimized for GPU usage. Utilize libraries and frameworks that leverage GPU acceleration effectively.
- Load Balancing: Distribute workloads evenly across available GPU to avoid overloading a single GPU while others are idle.
We explored how to deploy the NVIDIA GPU Operator in Kubernetes and outlined best practices for optimizing GPU utilization. By following the steps for deployment and implementing strategies for managing GPU resources, you can enhance the performance and efficiency of your AI workloads.
Remember to adjust GPU requests as needed, monitor performance with tools like Prometheus and DCGM, and optimize your workloads to make the most of your GPU resources. For any questions or additional support, feel free to reach out.
Happy deploying and optimizing!
For more insights and detailed guides on Kubernetes, be sure to check out my Kubernetes blog for the latest tips and best practices!


Pingback: NVIDIA GPU Deployment for AI in Kubernetes | by Nikhil Kumar | techbeatly | Sep, 2024 - AI App News
Pingback: NVIDIA GPU MIG Partitioning Guide - Techi Nik