
What Are Pods?
Pods are the smallest units in Kubernetes, it represents one or more containers that share storage, network resources, and specifications for how they should be running. They are considered the fundamental building blocks within a Kubernetes cluster, where application processing is managed.
Each pod is assigned a unique IP address within the cluster, which enables communication between containers within the pod and with other pods or services. Since pods are crucial to how applications run in Kubernetes, ensuring they work properly is important for the stability and performance of the services.
Pod Creation and Internal Components
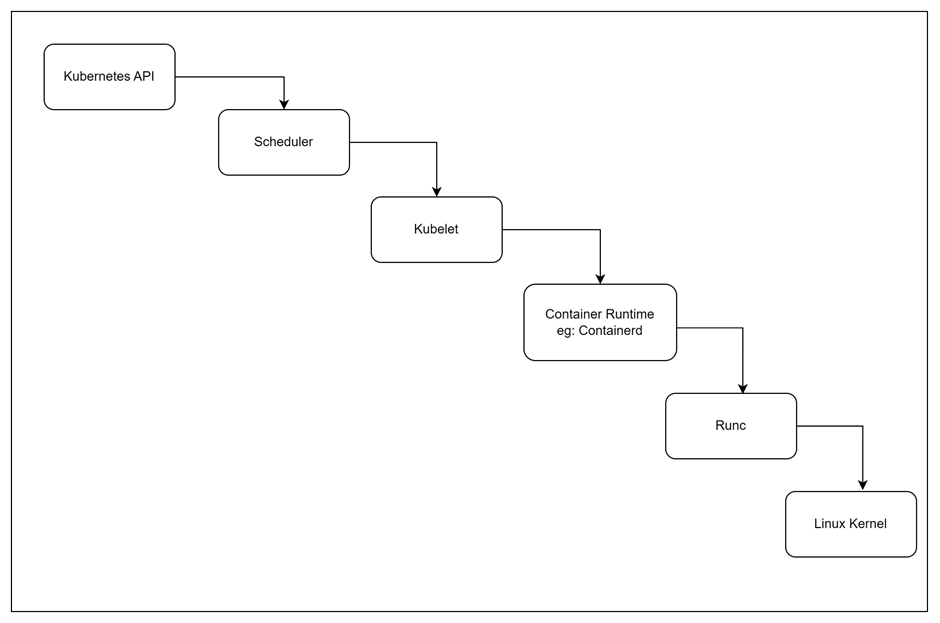
Pod Creation Request:
- When a Deployment or Pod is created in Kubernetes, it submits a request to the Kubernetes API Server.
Scheduler:
- The Kubernetes API Server sends the request to the Scheduler.
- The Scheduler selects an appropriate Node for the Pod based on resource availability, constraints, and policies.
Kubelet:
- Once a Node is chosen, the Scheduler sends the Pod specification to the Kubelet running on that Node.
- The Kubelet receives the Pod specifications and manages the Pod’s lifecycle on that Node.
Container Runtime:
- The Kubelet communicates with the Container Runtime (e.g., containerd) to handle container creation and execution.
- The Container Runtime interacts with
runcto manage the container processes.
RunC:
runcis a low-level container runtime responsible for creating and managing container processes based on the specifications provided by the Container Runtime.
Linux Kernel:
- The Linux Kernel handles container isolation and resource management, as instructed by
runc. - It ensures that the containers run in isolated environments and have access to the necessary resources.
Understanding these components is important for troubleshooting because it provides insight into where issues may arise within the Pod lifecycle, from scheduling and resource allocation to container execution. This knowledge helps you to identify and address problems more effectively by pinpointing the exact stage and component involved.
Why Troubleshooting Pods Matters
Troubleshooting pod failures is essential for maintaining the health and reliability of your Kubernetes environment. When a pod fails, it can disrupt your application, causing downtime or performance issues. Understanding the common causes of pod failures, such as image pull errors, memory issues, and CrashLoopBackOff states, allows you to quickly diagnose and resolve problems, minimizing their impact on your services.
Common Pod Issues
Image Pull Errors
Overview:
Image pull errors occur when Kubernetes is unable to retrieve the specified container image from the registry. These issues are commonly caused by incorrect image names or tags, missing credentials, or network connectivity problems. In air-gapped environments — where the cluster does not have direct internet access — such errors are particularly frequent. In these cases, a manual approach is required to load images onto a private registry within the cluster.
Diagnosis:
- Using
kubectl describe pod
The following command can be used to diagnose image pull errors:
root@rke2-server1:~# kubectl describe pod <pod-name> -n <namespace>In the output, look for the Events section, which shows something like:
Events:
Failed to pull image "myregistry.com/myimage:latest": rpc error: code = Unknown desc = Error response from daemon: manifest for myregistry.com/myimage:latest not foundSolutions:
- Fixing Incorrect Image Names or Tags: Ensure the image name and tag in your deployment are correct
- Updating Image Pull Secrets: If credentials are incorrect, they should be updated:
root@rke2-server1:~# kubectl create secret image-registry <secret-name> --docker-server=<registry-url> --docker-username=<username> --docker-password=<password> -n <namespace>- Ensuring Proper Network Connectivity: Test connectivity to the image registry from within the cluster test the connection to the registry properly using the curl command.
OOMKilled (Out of Memory Kills)
Overview:
OOMKilled errors happen when a container exceeds its allocated memory, leading to its termination by Kubernetes.
Diagnosis:
- Using
<strong>kubectl describe pod</strong>: To check for OOMKilled events, use:
root@rke2-server1:~# kubectl describe pod <pod-name> -n <namespace>Look for:
State: Terminated
Reason: OOMKilled- Monitoring Pod Memory Usage with
<strong>kubectl top pod</strong>: Monitor memory usage to prevent OOMKilled errors.
root@rke2-server1:~# kubectl top pod <pod-name> -n <namespace>Example Output:
root@rke2-server1:~# k top pod <pod-name> -n <namespace>
NAME CPU(cores) MEMORY(bytes)
cert-manager-7b86567ff4-8twck 50m 300Mi
root@rke2-server1:~#Solutions:
- Optimizing Container Resource Requests and Limits: Set appropriate memory requests and limits in your pod definition:
resources:
requests:
memory: "256Mi"
limits:
memory: "512Mi"- Analyzing and Reducing Memory Usage: Adjust application code or configurations to reduce memory consumption.
- Scaling Out Workloads: Use a Horizontal Pod Autoscaler (HPA) to distribute the load:
root@rke2-server1:~# kubectl autoscale deployment <deployment-name> --cpu-percent=50 --min=2 --max=10 -n <namespace>CrashLoopBackOff
Overview:
The CrashLoopBackOff state indicates that a pod is repeatedly failing to start, which can be caused by misconfigurations, application crashes, or missing dependencies.
Diagnosis:
- Checking Pod Logs with
<strong>kubectl logs</strong>: Check the logs of the failing pod:
root@rke2-server1:~# kubectl logs <pod-name> -n <namespace>Example Output:
root@rke2-server1:~# kubectl logs rook-ceph-osd-1-6647896c57-56c2x -n rook-ceph
Defaulted container "osd" out of: osd, log-collector, activate (init), expand-bluefs (init), chown-container-data-dir (init)
debug 2024-08-16T06:03:29.728+0000 7fcc6f699700 -1 monclient(hunting): handle_auth_bad_method server allowed_methods [2] but i only support [2]
debug 2024-08-16T06:03:29.728+0000 7fcc6e697700 -1 monclient(hunting): handle_auth_bad_method server allowed_methods [2] but i only support [2]
debug 2024-08-16T06:03:29.728+0000 7fcc6ee98700 -1 monclient(hunting): handle_auth_bad_method server allowed_methods [2] but i only support [2]
failed to fetch mon config (--no-mon-config to skip)
root@rke2-server1:~#- Reviewing Readiness and Liveness Probes: Review probe configurations in the pod definition:
livenessProbe:
httpGet:
path: /healthz
port: 8080
initialDelaySeconds: 3
periodSeconds: 3
readinessProbe:
httpGet:
path: /ready
port: 8080
initialDelaySeconds: 5
periodSeconds: 3Solutions:
- Fixing Misconfigurations or Code Issues
Resolve configuration errors or bugs in the application code that cause repeated crashes. - Adjusting Probe Settings
Modify probe settings to better match the application’s startup time:
initialDelaySeconds: 10
periodSeconds: 5- Ensuring Dependencies Are Available: Ensure services like databases are available before the pod starts:
initContainers:
- name: wait-for-db
image: busybox
command: ['sh', '-c', 'until nslookup db.example.com; do echo waiting for db; sleep 2; done;']Tools & Techniques: Using kubectl to Diagnose Pod Issues
kubectl describe pod
Usage:
The kubectl describe pod command provides detailed information about a pod’s status, events, and issues. This command can reveal important details such as error messages, container statuses, and reasons for failures.
Example:
root@rke2-server1:~# kubectl describe pod <pod-name> -n <namespace>Output:
Includes sections like Events showing error messages such as image pull errors or OOMKilled events.
kubectl logs
Usage:
The kubectl logs command is used to view container logs and diagnose runtime issues. It helps identify problems occurring during the container’s execution.
Example:
root@rke2-server1:~# kubectl logs <pod-name> -n <namespace>Output:
Shows the application’s output and errors, useful for troubleshooting crashes or misconfigurations.
kubectl top pod
Usage:
The kubectl top pod command monitors resource usage, such as memory and CPU, to identify potential issues related to resource limits or high usage.
Example:
root@rke2-server1:~# kubectl top pod <pod-name> -n <namespace>Output:
Displays resource usage metrics, such as CPU and memory, helping to detect if resource limits are being exceeded.
kubectl exec
Usage:
The kubectl exec command allows running commands inside containers for in-depth debugging and interaction with the running environment. Example:
root@rke2-server1:~# kubectl exec -it <pod-name> -n <namespace> -- bashOutput:
It provides a shell session inside the container, enabling direct inspection and troubleshooting of issues.
Best Practices for Avoiding Pod Failures
- Set Appropriate Resource Requests and Limits:
Resource requests and limits should be properly configured to prevent issues like OOMKilled errors. - Implement Robust Readiness and Liveness Probes:
Effective readiness and liveness probes are essential for detecting and resolving pod health issues promptly. - Regularly Monitor Pod Health and Resource Usage:
Continuous monitoring of pod health and resource usage helps in early detection of potential problems. - Ensure Proper Configuration Management and Version Control:
Accurate configuration management and version control practices prevent misconfigurations and maintain application stability.
By understanding and addressing common pod issues such as image pull errors, OOMKilled errors, and CrashLoopBackOff states, you can significantly improve the reliability and performance of your Kubernetes deployments. Utilizing tools like kubectl describe pod, kubectl logs, kubectl top pod, and kubectl exec allows for effective diagnosis and resolution of pod problems.
Implementing best practices, including setting appropriate resource requests and limits, using robust readiness and liveness probes, monitoring pod health, and ensuring proper configuration management, will help prevent pod failures and maintain a stable Kubernetes environment.
With these insights and techniques, you’ll be better equipped to troubleshoot and resolve pod issues, ensuring smoother operations and enhanced reliability in your Kubernetes cluster.
Thank you for reading! We hope these insights and techniques will aid you in troubleshooting and resolving pod issues more effectively. Stay tuned for more in-depth discussions on Kubernetes troubleshooting in our upcoming blog series. Feel free to leave comments or share your own experiences and tips.

